
Demo AI Quoting System with Fine-tuning and Quantization
A report + reflection on building demo AI quoting system by fine-tuning Qwen3-4B with a single RTX 4090, quantized to Q4_K_M GGUF, and benchmarked CPU vs GPU.
- Goal: Fine‑tune Qwen3‑4B; GPU (HF) vs CPU GGUF (Q4_K_M).
- Data: 1,099 rows; 70/15/15 split.
- Train: LoRA r=8, α=16, dropout=0; cutoff_len=2048; epochs=3; bf16.
- Eval: temperature=0.0; same system/instruction; JSON‑only outputs.
- Result: 100% JSON‑valid; CPU ~2× slower; ≤3‑pt accuracy drop.
This article is not only a technical report of the demo AI quote system, but also includes some thoughts on the rising AI Staff industry. This article can also represent my treasure memory for my internship experience. I enjoyed and learned a lot from it.
- Much thanks to the company for giving me, a freshman student who is still seeking knowledge, this opportunity.
- Much thanks to my advisors for their technical and development support.
- Also thanks to Cursor, an IDE but acting as my coding teacher.
0) Context#
- Company’s Goal: Applying “AI Staff” to manufacturing/distribution workflows
- Use case: Parse customer quote Excels/Images/PDFs → normalized JSON → matching price database.
- Why LLM vs rules: supports messy and varied document formats, long‑tail fields
I normalize each line item into this compact schema used throughout this post:
{"index": "", "model": "", "voltage": "", "spec": "", "unit": "", "num": ""}1) Model & Setup#
- Base model: Qwen3-4B-Instruct-2507 ↗
- Hardware: RTX 4090, i9-14900K
- Framework: LLaMA-Factory (SFT + LoRA) ↗, Llama.cpp (Quantization) ↗
- Approach: LoRA, GGUF (4-bit quant)
2) Data Processing & Formatting#
-
Source:
Thanks for my amazing colleagues, I was provided by Excel sheets that are already labelled in a great quality.
Anonymization and sharing policy#
I do not publish any company data. All examples here are redacted; all relevant data about any company is anonymized. I only show a 5‑line preview table with anonymized data for illustration. The full dataset is private.
All models/voltages/specs/units/quantities are anonymized via deterministic tokenization and bucketing (e.g., Vxx-Fyy-Sz, LV/MV/HV, U1/U2, ~10^n)
Why only Excel#
Although the company handles PDFs/images/Excels, this demo focuses on Excel quotes only. Future work: OCR pipeline → the same JSON schema.
序号 物料编码 货物(功能规格)描述 单位 数量 单价(元) 税率(%) 单价(元) labeled-型号 labeled-电压 labeled-规格 labeled-单位 labeled-数量 1 500****** Cable,F01,M1,10^2,C1,V01,A0,G0 U2 1 10^5 T1 10^5 V01-F01 LV 1*10^2U1 ~10^32 500****** Cable,F05,M1,10^1/10^1,C3+1,V01,A1,G0 U2 1 10^4 T1 10^5 V01-F05-S2 LV 3*10^1+1*10^1U1 ~10^33 500****** Cable,F03,M2,10^2,C4,V01,A1,G0 U2 1 10^4 T1 10^4 V01-F03-S2 LV 4*10^2U1 ~10^34 500****** Cable,F03,M2,10^2,C4,V01,A0,G0 U2 1 10^4 T1 10^4 V01-F03 LV 4*10^2U1 ~10^35 500****** Cable,F03,M2,10^2,C4,V01,A1,FR0 U2 1 10^4 T1 10^4 V01-F03-S2 LV 4*10^2U1 ~10^3 -
Processing & formatting:
Convert the dataset to a jsonl file in Alpaca format for supervised fine-tuning. A formal Alpaca json typically contain four components, which are instruction (prompt), input (context), output (desired response), and system (system prompt). For details, please refer to LLM dataset formats ↗ in Llama-Factory.
Here is the python script that helps me to process the datasets.
Data Processing Script
pythonimport argparse, json, re from pathlib import Path import pandas as pd DASH = r"[\--—–]" MODEL_COLS = [f"labeled{DASH}型号", "labeled-型号"] VOLT_COLS = [f"labeled{DASH}电压", "labeled-电压"] SPEC_COLS = [f"labeled{DASH}规格", "labeled-规格"] UNIT_COLS = [f"labeled{DASH}单位", "labeled-单位"] NUM_COLS = [f"labeled{DASH}数量", "labeled-数量"] labeled_PATTERNS = [f"^labeled{DASH}型号$", f"^labeled{DASH}电压$", f"^labeled{DASH}规格$", f"^labeled{DASH}单位$", f"^labeled{DASH}数量$"] DEFAULT_INSTRUCTION = ( "Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string." ) DEFAULT_SYSTEM = ( "Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string." ) # convert to string def to_str(x): if pd.isna(x): return "" s = str(x).strip() # collapse internal whitespace s = re.sub(r"\s+", " ", s) # drop .0 to avoid ints coming from Excel if re.match(r"^\d+\.0$", s): s = s[:-2] return s # Identify labeled columns which are the labeled columns def is_labeled_col(colname: str) -> bool: if colname is None: return False name = str(colname).strip() for pat in labeled_PATTERNS: if re.match(pat, name): return True return False # This is to prevent blank columns def pick_first_present(row, candidates): """Find the first candidate column name that exists (regex or literal).""" for cand in candidates: if any(ch in cand for ch in "--—–[]^$\\"): for c in row.index: if re.match(cand, str(c).strip()): return to_str(row[c]) else: if cand in row.index: return to_str(row[cand]) return "" # Join all NON-labeled columns values from the row into one string (values only), adding | for segmentation def build_input_values_only(row): """Join all NON-labeled cell values from the row into one string (values only).""" vals = [] for col in row.index: name = str(col).strip() if is_labeled_col(name): continue v = to_str(row[col]) if v != "": vals.append(v) return " | ".join(vals) # output object are excatly the labeled columns, but in json format def make_output_obj(row, one_based_index): return { "index": str(one_based_index), "model": pick_first_present(row, MODEL_COLS), "voltage": pick_first_present(row, VOLT_COLS), "spec": pick_first_present(row, SPEC_COLS), "unit": pick_first_present(row, UNIT_COLS), "num": pick_first_present(row, NUM_COLS), } def process_excel(path, sheet, instruction, system, output_as_object): try: df = pd.read_excel(path, sheet_name=sheet) except Exception as e: print(f"[WARN] Skip {path} (read error): {e}") return [] df = df.dropna(how="all") records = [] for i, row in df.iterrows(): index_1_based = i + 1 input_text = build_input_values_only(row) input_text = f"{index_1_based}# | {input_text}" if input_text else f"{index_1_based}#" out_obj = make_output_obj(row, index_1_based) rec = { "instruction": instruction, "input": input_text, "output": (out_obj if output_as_object else json.dumps(out_obj, ensure_ascii=False)), } if system: rec["system"] = system records.append(rec) return records def iter_excels(paths): for p in paths: p = Path(p) if p.is_dir(): for f in sorted(p.rglob("*.xls*")): yield f elif p.is_file() and p.suffix.lower().startswith(".xls"): yield p def main(): ap = argparse.ArgumentParser(description="Convert a folder of Excel files to Alpaca JSONL (values-only input, labeled columns for output).") ap.add_argument("--in", dest="inputs", nargs="+", required=True, help="Folder(s) and/or file(s). Folders scanned recursively.") ap.add_argument("--sheet", default="labeled-1", help="Sheet index (int) or name (str). Default 0.") ap.add_argument("--out", default="labeled_AI_Quote_821.jsonl", help="Output JSONL.") ap.add_argument("--instruction", default=DEFAULT_INSTRUCTION, help="Instruction text.") ap.add_argument("--no-system", action="store_true", help="Omit the system field.") ap.add_argument("--output-as-object", action="store_true", help="Store 'output' as a JSON object instead of a JSON string.") args = ap.parse_args() sheet = int(args.sheet) if args.sheet.isdigit() else args.sheet system = None if args.no_system else DEFAULT_SYSTEM all_recs, files = [], list(iter_excels(args.inputs)) for f in files: recs = process_excel(f, sheet, args.instruction, system, args.output_as_object) print(f"[OK] {f.name}: {len(recs)} rows") all_recs.extend(recs) Path(args.out).parent.mkdir(parents=True, exist_ok=True) with open(args.out, "w", encoding="utf-8") as w: for r in all_recs: w.write(json.dumps(r, ensure_ascii=False) + "\n") print(f"[DONE] Wrote {len(all_recs)} samples from {len(files)} file(s) → {args.out}") if __name__ == "__main__": main()-
Instruction:
“Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like ’
#’, set index to ' ' (no ’#’). If the input has no index, set index to an empty string.” -
System:
“Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like ’
#‘,copy the number and output it as ' ' (no ’#’); otherwise set index to an empty string.” -
Input:
Extracted from the strings of each row in the Excel table, whereas adding ’|’ delimiter to separate fields and adding ’#’ after the index number that are acquired from Excel table row numbers to distinguished with real row values.
Using index to mark each row is to support input with multiple lines in the future. This can still preserves a 1:1 mapping between inputs and outputs via
index, which keeping postprocessing simple without changing the schema. -
Output:
The output format is
{"index": "", "model": "", "voltage": "", "spec": "", "unit": "", "num": ""}The output component is extracted from the labeled-columns, which are the annotated data, except for index number. The index numbers in output are also acquired from the Excel table row numbers. -
Example Processed Data
5-line preview of Alpaca-style JSONL file, ready for Fine-tuning.
jsonl{"instruction":"Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string.","input":"1# | 1 | Cable | F04-LV-2*10^1 | U1 | ~10^3 | 10^1 | 10^5","output":"{\"index\":\"1\",\"model\":\"F03\",\"voltage\":\"LV\",\"spec\":\"2*10^1\",\"unit\":\"U1\",\"num\":\"~10^3\"}","system":"Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string."} {"instruction":"Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string.","input":"2# | 2 | Cable | F04-LV-3*10^1 | U1 | ~10^2 | 10^1 | 10^4","output":"{\"index\":\"2\",\"model\":\"F03\",\"voltage\":\"LV\",\"spec\":\"3*10^1\",\"unit\":\"U1\",\"num\":\"~10^2\"}","system":"Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string."} {"instruction":"Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string.","input":"3# | 3 | Cable | F04-S2-LV-5*10^1 | U1 | ~10^2 | 10^1 | 10^4","output":"{\"index\":\"3\",\"model\":\"F03-S2\",\"voltage\":\"LV\",\"spec\":\"5*10^1\",\"unit\":\"U1\",\"num\":\"~10^2\"}","system":"Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string."} {"instruction":"Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string.","input":"4# | 4 | Cable | F04-S2-LV-2*10^1 | U1 | ~10^3 | 10^1 | 10^5","output":"{\"index\":\"4\",\"model\":\"F03-S2\",\"voltage\":\"LV\",\"spec\":\"2*10^1\",\"unit\":\"U1\",\"num\":\"~10^3\"}","system":"Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string."} {"instruction":"Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string.","input":"5# | 5 | Cable | F04-S2-LV-4*10^1 | U1 | ~10^3 | 10^1 | 10^5","output":"{\"index\":\"5\",\"model\":\"F03-S2\",\"voltage\":\"LV\",\"spec\":\"4*10^1\",\"unit\":\"U1\",\"num\":\"~10^3\"}","system":"Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string."}
-
2.5) Train/Val/Test Split#
I split the 1099-row Alpaca JSONL into train/val/test with a fixed seed to avoid overfitting problem and to keep results reproducible.
-
Split: 70/15/15 with seed 42
-
Counts: train 768, val 165, test 166
Train/Val/Test Split Script
pythonimport argparse, json, random from collections import defaultdict from pathlib import Path FIELDS = ["index","model","voltage","spec","unit","num"] def read_jsonl(p): data = [] with open(p, "r", encoding="utf-8") as f: for line in f: if not line.strip(): continue rec = json.loads(line) # ground truth may be a JSON string → object out = rec.get("output") if isinstance(out, str): try: rec["output"] = json.loads(out) except Exception: rec["output"] = None data.append(rec) return data def write_jsonl(path, rows): path.parent.mkdir(parents=True, exist_ok=True) with open(path, "w", encoding="utf-8") as w: for r in rows: w.write(json.dumps(r, ensure_ascii=False) + "\n") def stratify_by_model(rows): buckets = defaultdict(list) for r in rows: key = "" out = r.get("output") or {} if isinstance(out, dict): key = out.get("model","").strip() buckets[key].append(r) return buckets def split_buckets(buckets, ratios, seed): train, val, test = [], [], [] rnd = random.Random(seed) for _, bucket in buckets.items(): rnd.shuffle(bucket) n = len(bucket) n_train = int(n * ratios[0]) n_val = int(n * ratios[1]) train += bucket[:n_train] val += bucket[n_train:n_train+n_val] test += bucket[n_train+n_val:] return train, val, test def main(): ap = argparse.ArgumentParser() ap.add_argument("--in", dest="inp", required=True) ap.add_argument("--outdir", default="./") ap.add_argument("--seed", type=int, default=42) ap.add_argument("--ratios", nargs=3, type=float, default=[0.7,0.15,0.15]) ap.add_argument("--no_stratify", action="store_true", help="If set, use pure random split instead of stratifying by output.model") args = ap.parse_args() rows = read_jsonl(args.inp) rows = list({r["input"]: r for r in rows}.values()) # de-dup by input rnd = random.Random(args.seed) if args.no_stratify: rnd.shuffle(rows) n = len(rows) n_train = int(n*args.ratios[0]) n_val = int(n*args.ratios[1]) train, val, test = rows[:n_train], rows[n_train:n_train+n_val], rows[n_train+n_val:] else: buckets = stratify_by_model(rows) train, val, test = split_buckets(buckets, args.ratios, args.seed) outdir = Path(args.outdir) write_jsonl(outdir/"train_labeled_AI_Quote_821.jsonl", train) write_jsonl(outdir/"val_labeled_AI_Quote_821.jsonl", val) write_jsonl(outdir/"test_labeled_AI_Quote_821.jsonl", test) print(f"Total {len(rows)} → train {len(train)}, val {len(val)}, test {len(test)}") if __name__ == "__main__": main()
3) Fine-tuning#
Supervised fine‑tuning (SFT) of Qwen3‑4B‑Instruct with LoRA; the model can then be fine-tuned to limit the outputs be strict JSON and parsed the input’s information to the corresponding fields in output.
-
Dataset size: ~1099 JSON objects, Alpaca format (instruction/input/output/system)
-
Sequence: cutoff_len=2048
-
Optimizer/schedule: AdamW (adamw_torch), cosine LR, lr=5e‑5, warmup=0, max grad norm=1.0
-
Training: epochs=3, batch size=2, grad accumulation=8 (effective batch size 16), bf16 on RTX 4090
-
LoRA: rank=8, alpha=16, dropout=0, target=all
-
Logging/saving: log every 5 steps, save every 100 steps; loss plot enabled
-
Output: LoRA adapters, which would later be merged for HF inference and GGUF
llamafactory-cli Command I used
bashllamafactory-cli train \ --stage sft \ --do_train True \ --model_name_or_path Qwen/Qwen3-4B-Instruct-2507 \ --preprocessing_num_workers 16 \ --finetuning_type lora \ --template qwen3_nothink \ --flash_attn auto \ --dataset_dir data \ --dataset train_labeled_AI_Quote_821 \ --cutoff_len 2048 \ --learning_rate 5e-05 \ --num_train_epochs 3.0 \ --max_samples 100000 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --packing False \ --enable_thinking True \ --report_to none \ --output_dir saves/Qwen3-4B-Instruct-2507/lora/train_2025-08-22-17-27-45 \ --bf16 True \ --plot_loss True \ --trust_remote_code True \ --ddp_timeout 180000000 \ --include_num_input_tokens_seen True \ --optim adamw_torch \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target all
The built-in Export function can merge the base model with LoRA adapters.
4) Quantization#
Quantize the merged HF model to GGUF for CPU inference with llama.cpp.
Why Quantize#
Quantization can reduce precision (in this task, bf16 → 4-bit) so models are ~3–4× smaller than bf16 in practice, with a small accuracy trade-off. Exporting to GGUF, llama.cpp’s single-file format bundling weights, tokenizer, and metadata, then run Q4_K_M on CPU for predictable latency and low memory.
Mistakes I Made#
In my first attempt, I first quantized the base model and tried to attach the LoRA adapters in llama.cpp. The adapter wasn’t actually applied (may due to format/target mismatch), so outputs reverted to the base model. In the smoke test shown in the screenshot, the ‘voltage’ field disappeared.
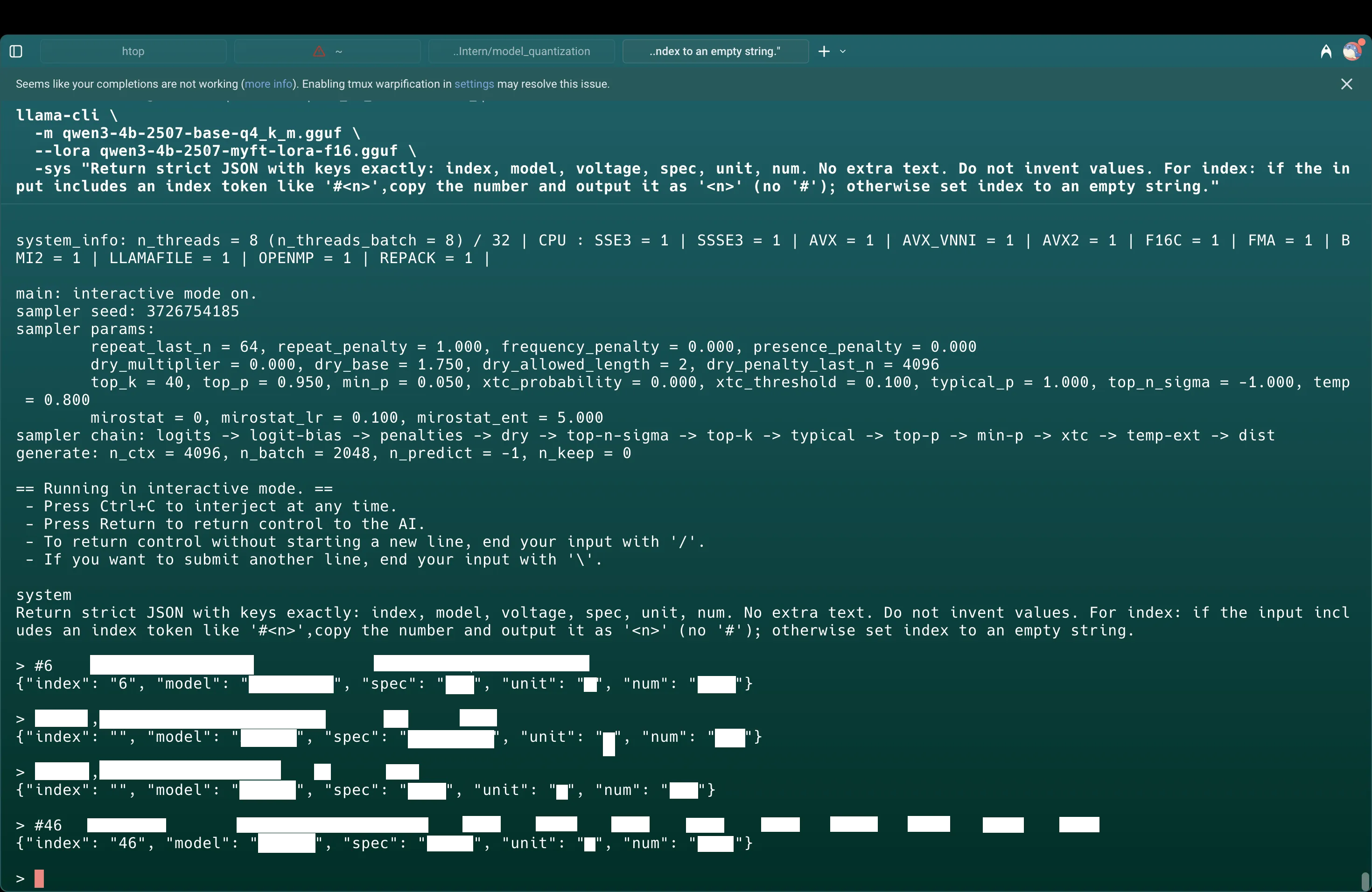
The correct path is to first merge the LoRA into the base in HF, verify, then convert to GGUF and quantize.
-
llamacpp Command I used
bashcd to/llama.cpp python3 convert-hf-to-gguf.py \ "Qwen3-4B-2507-ft-merged" \ --outtype bf16 \ --outfile qwen3-4b-2507-ft-merged-bf16.gguf ./build/bin/llama-quantize \ qwen3-4b-2507-ft-merged-bf16.gguf \ qwen3-4b-2507-ft-merged-q4_k_m.gguf \ Q4_K_M
5) Evaluation#
In order to test the model accuracy in this task, and identify the degradation of accuracy after quantization to 4-bit, this evaluator python script helps to link the two backends (Huggingface transformers vs llama.cpp) to test the score and latency on the original bf16 hf model and the quantized 4-bit gguf model.
There are three evaluation dimensions:
- The validity of output JSON format.
- The accuracy of each field in the output.
- The latency (average responding time for one input)
Several deterministic settings are
-
temperature=0.0, to minimize the creativity for parsing task
-
aligned top_p and top_k. Huggingface transformer’s default is top_p=1, top_k=50, whereas llama.cpp’s default is top_p=0.95, top_k=40. In this evaluation, the temperature = 0.0 would make top_p and top_k irrelevant theoretically. In my first experiment, I did not set temperature to 0.0, which causing the accuracy of the merged fine-tuned hf model to degrade, even lower than the quantized gguf model.
-
Other params in response generation are default.
-
Prompt Template:
plaintextSystem: Return strict JSON with keys exactly: index, model, voltage, spec, unit, num. No extra text. Do not invent values. For index: if the input includes an index token like '<n>#',copy the number and output it as '<n>' (no '#'); otherwise set index to an empty string. Instruction: Given one table row of cables, produce ONLY a JSON object with keys exactly: index, model, voltage, spec, unit, num. If the input contains an index token like '<n>#', set index to '<n>' (no '#'). If the input has no index, set index to an empty string. Input: 1# | 1 | Cable | F04-LV-2*10^1 | U1 | ~10^3 | 10^1 | 10^5 Assistant:Below is the Evaluator Script:
Evaluator Script
pythonimport argparse, json, re, time, math from statistics import median # different fields in output that needs different accuracy calcualtion FIELDS = ["index","model","voltage","spec","unit","num"] # process the test jsonl file def read_jsonl(p): rows=[] with open(p,"r",encoding="utf-8") as f: for line in f: if not line.strip(): continue r=json.loads(line) if isinstance(r.get("output"),str): try: r["output"]=json.loads(r["output"]) except Exception: r["output"]=None rows.append(r) return rows # the system prompt and instrction and input def build_prompt(r): sys_=(r.get("system") or "").strip() inst=(r.get("instruction") or "").strip() inp =(r.get("input") or "").strip() parts=[] if sys_: parts.append(f"System: {sys_}") if inst: parts.append(f"Instruction: {inst}") if inp : parts.append(f"Input: {inp}") parts.append("Assistant:") return "\n".join(parts) # extract the json from the model output def extract_json(text): # try fenced JSON block first m=re.search(r"```(?:json)?\s*({[\s\S]*?})\s*```", text, flags=re.I) if m: s=m.group(1) try: return json.loads(s) except Exception: pass # fall back to the first minimal-brace object m=re.search(r"\{[\s\S]*?\}", text) if not m: return None try: return json.loads(m.group(0)) except Exception: return None # evaluate the rows def eval_rows(rows, preds, times_ms): n=len(rows) valid=sum(1 for p in preds if isinstance(p,dict)) correct=[0]*len(FIELDS) for r,p in zip(rows,preds): gt=r.get("output") or {} for i,k in enumerate(FIELDS): if isinstance(p,dict) and str(p.get(k,"")).strip()==str(gt.get(k,"")).strip(): correct[i]+=1 acc={k: correct[i]/n for i,k in enumerate(FIELDS)} return { "n": n, "json_valid": valid/n if n else 0.0, "acc": acc, "latency": { "p50_ms": median(times_ms) if n else 0, "p95_ms": sorted(times_ms)[int(math.ceil(0.95*n))-1] if n else 0 } } def run_hf(model_path, rows, max_new_tokens=256, temperature=0.0, device="cuda:0", dtype="bf16", progress=False, dump_fails=0, top_p=0.9, top_k=40): import torch from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig from transformers import logging as hf_logging torch_dtype = torch.bfloat16 if dtype=="bf16" else torch.float16 tok = AutoTokenizer.from_pretrained(model_path, use_fast=True) if tok.pad_token_id is None and tok.eos_token_id is not None: tok.pad_token = tok.eos_token model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, torch_dtype=torch_dtype) model.eval() hf_logging.set_verbosity_error() preds=[]; times=[] total=len(rows) dump_left=int(dump_fails) if dump_fails else 0 for i,r in enumerate(rows): prompt = build_prompt(r) t0=time.time() ids = tok(prompt, return_tensors="pt") input_device = getattr(model, "device", None) if input_device is None: input_device = next(model.parameters()).device ids = ids.to(input_device) do_sample = bool(temperature) and float(temperature) > 0.0 gen_cfg = GenerationConfig( do_sample=do_sample, temperature=float(temperature) if do_sample else None, eos_token_id=tok.eos_token_id, pad_token_id=tok.pad_token_id, # Pass through user-provided top_p/top_k even if not sampled; need to align with cpu gguf model top_p=(float(top_p) if top_p is not None else None), top_k=(int(top_k) if top_k is not None else None), ) out = model.generate(**ids, generation_config=gen_cfg, max_new_tokens=max_new_tokens) txt = tok.decode(out[0][ids["input_ids"].shape[1]:], skip_special_tokens=True).strip() times.append((time.time()-t0)*1000) pred = extract_json(txt) preds.append(pred) if progress: status = "ok" if isinstance(pred, dict) else "fail" print(f"[hf {i+1}/{total}] {times[-1]:.0f} ms json={status}", flush=True) if not isinstance(pred, dict) and dump_left>0: print(f"--- RAW_FAIL {i+1}/{total} ---\n{txt}\n--- END_RAW_FAIL ---", flush=True) dump_left-=1 return preds, times def run_llamacpp(gguf_path, rows, max_tokens=256, threads=16, temperature=0.0, n_gpu_layers=0, progress=False, dump_fails=0, top_p=0.9, top_k=40): from llama_cpp import Llama llm = Llama(model_path=str(gguf_path), n_threads=threads, n_gpu_layers=n_gpu_layers, n_ctx=4096, logits_all=False, verbose=False) preds=[]; times=[] total=len(rows) dump_left=int(dump_fails) if dump_fails else 0 for i,r in enumerate(rows): prompt = build_prompt(r) t0=time.time() # Align semantics with HF and pass through user values even if greedy if temperature and float(temperature) > 0.0: llama_temp = float(temperature) else: llama_temp = 0.0 llama_top_p = (float(top_p) if top_p is not None else None) llama_top_k = (int(top_k) if top_k is not None else None) out = llm(prompt, max_tokens=max_tokens, temperature=llama_temp, top_p=llama_top_p, top_k=llama_top_k, echo=False) txt = out["choices"][0]["text"] times.append((time.time()-t0)*1000) pred = extract_json(txt) preds.append(pred) if progress: status = "ok" if isinstance(pred, dict) else "fail" print(f"[llamacpp {i+1}/{total}] {times[-1]:.0f} ms json={status}", flush=True) if not isinstance(pred, dict) and dump_left>0: print(f"--- RAW_FAIL {i+1}/{total} ---\n{txt}\n--- END_RAW_FAIL ---", flush=True) dump_left-=1 return preds, times def main(): ap=argparse.ArgumentParser() ap.add_argument("--split", required=True) ap.add_argument("--engine", choices=["hf","llamacpp"], required=True) ap.add_argument("--hf_model", help="Path to merged HF model (engine=hf)") ap.add_argument("--gguf", help="Path to GGUF (engine=llamacpp)") ap.add_argument("--max_tokens", type=int, default=256) ap.add_argument("--temperature", type=float, default=0.1) ap.add_argument("--threads", type=int, default=16) ap.add_argument("--device", default="auto") ap.add_argument("--dtype", choices=["bf16","fp16"], default="bf16") ap.add_argument("--n_gpu_layers", type=int, default=0, help="llama.cpp: layers to offload to GPU (0 = CPU only)") ap.add_argument("--progress", action="store_true", help="Print per-row progress") ap.add_argument("--show_samples", type=int, default=0, help="Print first N (input, pred, gt) triplets for inspection") ap.add_argument("--dump_fails", type=int, default=0, help="Print raw model output for first N failures") ap.add_argument("--top_p", type=float, default=None, help="Sampling nucleus probability (both engines). Ignored if temperature=0") ap.add_argument("--top_k", type=int, default=None, help="Sampling top-k (both engines). Ignored if temperature=0; in llama.cpp, 0 disables") args=ap.parse_args() rows = read_jsonl(args.split) if args.engine=="hf": preds,times = run_hf(args.hf_model, rows, max_new_tokens=args.max_tokens, temperature=args.temperature, device=args.device, dtype=args.dtype, progress=args.progress, dump_fails=args.dump_fails, top_p=args.top_p, top_k=args.top_k) else: preds,times = run_llamacpp(args.gguf, rows, max_tokens=args.max_tokens, threads=args.threads, temperature=args.temperature, n_gpu_layers=args.n_gpu_layers, progress=args.progress, dump_fails=args.dump_fails, top_p=args.top_p, top_k=args.top_k) if args.show_samples > 0: k = min(args.show_samples, len(rows)) for i in range(k): sample = { "input": (rows[i].get("input") or "")[:2000], "pred": preds[i], "gt": rows[i].get("output") } print(json.dumps({"sample": i+1, **sample}, ensure_ascii=False)) print(json.dumps(eval_rows(rows, preds, times), ensure_ascii=False, indent=2)) if __name__=="__main__": main()
6) Results#
-
Merged LoRA Qwen3-4B bf16 model using Transformers running on GPU
json{ "n": 166, "json_valid": 1.0, "acc": { "index": 1.0, "model": 0.8554216867469879, "voltage": 0.891566265060241, "spec": 0.891566265060241, "unit": 0.9759036144578314, "num": 0.927710843373494 }, "latency": { "p50_ms": 3586.2115621566772, "p95_ms": 3607.1810722351074 } } -
Quantized Q4_K_M gguf model using llama.cpp running on CPU
json{ "n": 166, "json_valid": 1.0, "acc": { "index": 1.0, "model": 0.8373493975903614, "voltage": 0.8975903614457831, "spec": 0.8975903614457831, "unit": 0.963855421686747, "num": 0.8975903614457831 }, "latency": { "p50_ms": 7235.821008682251, "p95_ms": 7819.983243942261 } } -
Result Table
Deployment json_valid index model voltage spec unit num p50 (s) p95 (s) n GPU (HF, bf16) 1.00 1.000 0.855 0.892 0.892 0.976 0.928 3.59 3.61 166 CPU (GGUF Q4_K_M) 1.00 1.000 0.837 0.898 0.898 0.964 0.898 7.24 7.82 166 Both deployments produced perfectly valid JSON. CPU Q4_K_M was ~2x slower as expected but remained competitive on most fields with minor differences: -1.8% accuracy on model, -1.2% accuracy on unit, -3% accuracy on num.
7) Reflection#
Reflection and Future Work#
This project taught me that small fine-tuned models; a reliable evaluation loop; quantization on CPU can build a useful automation and easy deployment.
Two important lessons I learned:
- merge LoRA before quantization
- deterministic decoding (temperature=0.0 + early stop) to keep JSON valid and latency stable in parsing task scenario.
Next steps I will take:
- Logging and Recording Tokens/sec, prompt tokens, and generated tokens for both backends.
- Normalized accuracy, adding another evaluation scope.
- Ablation of different Quant Types or LoRA parameters.
- Add a simple stop at the first “}” and document its latency gain.
Some Thoughts on ‘AI Staff’#
I can 100% ensure that ‘AI Staff’ is becoming a real and rising industry in this modern society, that is already deployed in reality to replace some simple tasks human can do. It is moving from concept to reality. With a small model can specialize for routine office tasks when given high‑quality labeled data. With quantization, the same model can run on a consumer GPU or even on CPU via llama.cpp. Considering Costs, for production, only small models can be applicable to be ‘AI Staff’ to replace human with good enough accuracy, predictable latency, and affordable hardware. Large models remain impressive generalists in every possible tasks, but their run‑costs and latency don’t yet justify replacing people for narrow, structured tasks.
Moreover, My biggest lessons weren’t only fine‑tuning and quantization mechanics. It is the workflow around them like using Huggingface Hub private repo to store model weights, tracking versions and metrics, building simple and reproducible evaluation. That discipline I learned made the results trustworthy and easy to iterate on for me in the future.